
What is Duplicate content in SEO? Reasons and Remedies.
Are you here to know what is duplicate content in SEO? Let’s dig it out.
Duplicate content is not a mystery, as the name reveals itself. Content that is identical or near identical to the other content is considered duplicate content. In SEO, it becomes an issue when this duplicate content is accessible via multiple URLs.
Even if you haven’t created duplicate content, your site might still contain duplicate content and hamper your SEO somehow.
Let’s dive deeper into duplicate content and discover how it occurs and how we can fix it.
# What is duplicate content in SEO?
Duplicate content in SEO is content that is similar or near similar to the other content that is accessible via multiple URLs, not only on your site but on the internet.
Duplicate content does not add value to the visitors being the copied version and also confuses or misleads search engines. They could not decide which URL to prefer and rank higher in SERPs. Consequently, search engines might prioritize other URLs over both, resulting in their lower rankings.
For instance, if we publish a similar article under two different URLs within our site like this- “xyz.com/blog/seo/” and “xyz.com/seo/” or I publish it on a different website with the URL- “abc.com/blog/seo/” all these will be referred to as duplicate content.
In the above case, you may not have created the two different URLs yourself, but this may occur due to the modern CMS.
Why does duplicate content in SEO matter?
Duplicate content matters for search engines as well as for site owners. Search engines might confuse which URL to index, which to rank, and to which URL link equity should be shared. And the site owners may face traffic losses and lower rankings, and no page can receive the visibility it can receive as a single piece.
Following are a few reasons why duplicate content hampers your site’s SEO.
1. Unfriendly URLs in SERPs and traffic loss
Let’s say your content is accessible via the following URLs:
1. xyz.com/page/
2. xyz.com/page/?utm_content=buffer&utm_medium=social
3. xyz.com/category/page/
To us, all are similar as they lead to the same content, but to Google, all are different. In SEO, URLs should be well-optimized, which can encourage users to make click.
The first one is the main and optimized version and should appear in the results. Google might confuse and may show any of the three in the search results.
The unoptimized and unfriendly URL may appear in front of users, and they might not click it. This will result in a Loss of organic traffic and lower CTR, and consequently, you may be swapped from the SERPs.
2. The wrong version ranks in SERPs.
When you have near duplicate content on your site, Google may rank the content based on its understanding, and the wrong version of content may rank on SERPs.
3. Dilution of link equity
When identical or near identical content is accessible via different URLs. Both may rank and attract backlinks individually. This is the dilution of link equity between both URLs. Contrary to this, if only one piece of content was present, it would have obtained all of the backlinks and would have ranked higher in the SERPs.
4. Waste crawl budget
Google crawls a website to discover new content on the site by following the internal links on existing pages. Also, to discover any updates in the pre-existing pages.
If you have duplicate or near duplicate content on your site, you are wasting the crawl budget that could be used to crawl new and more important pages rather than crawling the duplicate content over and over.
Moreover, duplicate content may delay the crawling of new pages.
# How does duplicate content affect the user? Does Google penalize it for it?
According to Google, it usually does not penalize site owners for having duplicate content unless they do it to trick and manipulate search results.
This does not imply that you start creating duplicate content or publishing scraped content on your site.
Having similar content on your site is not a good practice. Although Google does not penalize you, your site’s SEO gets hampered. You may face Ranking fluctuations, Loss of organic traffic, and more. You can read here what Google says about duplicate content.
# What are the Common causes of duplicate content in SEO?
Nobody creates duplicate content intentionally, and usually, it’s a technical issue. There are plenty of causes that may create duplicate content on a site or the web. We’ll discuss them here one by one.
1. Faceted navigation
This is usually seen on the e-commerce website, where visitors sort or filter the products based on different criteria such as size, color, material, cost, and more.
This adds up the parameters at the end of the URLs, which creates numerous duplicates or near-duplicate content of the same product.
2. Session IDs
Another cause of duplicate content can be the session IDs that are different for each user. Site owners do this to track their visitors. When a visitor visits your site, a session ID is generated for him and stored in the URLs, which creates duplicate content.
For example- These are the session Ids of two different visitors.
xyz.com?sessionId=jow8082345hnfn9234
Xyz.com?sessionId=pjk763646gfh76
To avoid this issue, you can canonicalize all the URLs to the preferred version.
3. HTTPS vs. HTTP
Duplicate content may arise if you are inconsistent with the HTTPS and HTTP versions of your page.
If you have a secure HTTPS version, make sure you only use HTTPS all over your site. If you have similar content on the HTTP version, make sure to redirect it to HTTPS to avoid duplicate content issues.
4. Non-www vs. www
Another cause can be the WWW and non-WWW versions of your pages. If your content is accessible via both versions, make sure to redirect the one to another version. And make it consistent throughout your website to avoid duplicate content issues.
5.URLs are case-sensitive
Unlike Bing, URLs are case-sensitive for Google, which means Google considers the upper case and lower case URLs as two different URLs, which might create a duplicate content issue on your site. According to Google, you can use any case, but it must be consistent in your URLs
For instance, the following three URLs are different URLs for Google.
- xyz.com/SEO
- xyz.com/seo
- xyz.com/SeO
6. Trailing slashes vs. non-trailing-slashes
What do you think of the following two URLs?
- xyz.com/blog/
- xyz.com/blog
The URLs with trailing slashes and without them are two different URLs for Google.
Google considers it ideal when only one version loads and the other redirects to it.
If you are able to access your content via both URLs (with and without trailing slash), it might create a duplicate content issue on your site.
To avoid this issue, you can choose one format and redirect the other to it. Also, while internally linking your content, you must link your preferred version.
You can learn more about trailing and non-trailing slashes here.
7. Print-friendly and original URL
Your CMS might have created printer-friendly URLs that may lead to duplicate content issues on your site. Printer-friendly URLs serve similar content but are free from ads, navigation, and web junk.
It might appear like this-
- xyz.com/page
- xyz.com/print/page
You can avoid this by canonicalizing the print URL to the original URL.
8. Mobile-friendly URLs
Your site may contain different versions of URLs to serve on different devices, which are great for user experience. However, they may create a duplicate content issue on your site, similar to print-friendly URLs. For instance-
- xyz.com/page
- m.xyz.com/page
To avoid this issue, you can canonicalize the mobile version of your page to the original version.
9. AMP URLs
AMP URLs are duplicate versions of original pages that are created to speed up the loading speed to enhance the user experience. The URLs may appear like this-
- xyz.com/page
- xyz.com/amp/page
To avoid the duplicate content issue, you can canonicalize the AMP version of the content to the non-AMP version to signal to Google that this is a different version of the same content.
10. Content syndication and content scraping
Another major reason for duplicate content in SEO is improper content syndication and content scraping.
If you syndicate your content and the owner doesn’t link you back will place duplicate content on the web, and a similar goes with content scraping when different websites scrap your content without your consent and publish it on their site. In both situations, duplicate content is published on the internet and poses confusion to search engines.
11. Paginated comments
Many CMS, including WordPress, has an option of paginated comments. This increases the page loading speed but may create multiple versions of the same URL leading to duplicate content issues on your website. For instance, these are the URLs created due to the paginated comments-
- xyz.com/post/
- xyz.com/post/comment-page-2
- xyz.com/post/comment-page-3
To resolve this issue, either you can turn off comment pagination on your site or noindex the paginated pages.
12. Accessibility of your index pages.
Due to your server misconfigurations, your website may be accessed via multiple URLs.
For example-
https://www.xyz.com/index.html
https://www.xyz.com/index.php
https://www.xyz.com/index.asp
https://www.xyz.com/index.aspx
To prevent duplicate content issues on your site, make sure to serve your homepage by choosing a specific URL and 301 redirect the others to your preferred URL.
13. Localization and hreflang
You may end up creating duplicate content on your site when you try to serve your identical or near-identical content in different geographical regions in the same language.
For instance, You are running two different sites for Canada and US, and both are in the same language- English. There is probably a lot of content duplication. To avoid this issue, you can indicate to search engines the connection between both versions by using hreflang tags.
# How to check duplicate content in SEO?
You can audit duplicate content on your website with many tools available on the market. Here, we’ll suggest two tools that can be useful to you.
1. Google Search Console
Open your Google search console account and navigate to the performance tab and then the search result tab. Here you can discover the URLs that might be causing the content duplication issue on your site.
Check for these common issues in GSC.
- URLs with HTTP and HTTPS versions
- URLs with www and non-www version
- URLs with trailing slash “/” and without it
- URLs with query parameters and without it
- URLs with uppercase and lowercase variation
Moreover, you can also use Google Search Console’s “Index Coverage report” to discover duplicate content within your site: You can search for the given errors-
- Duplicate without user-selected canonical, where you haven’t canonicalized a specific version.
- Duplicate, Google chose a different canonical than the user: It bypasses the canonical tags and chooses the URLs themselves.
- Duplicate-The URL you submitted in the sitemap is not selected as canonical:
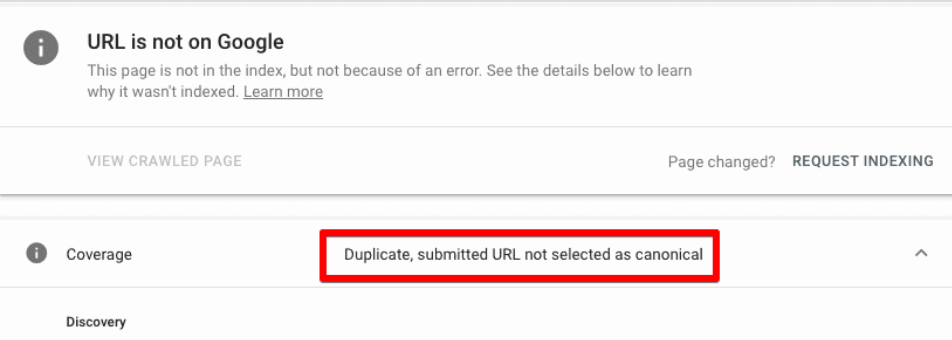
You can also use its URL Inspection tool to discover how Google treats your URLs.
2. Ahrefs’ Site Audit Tool
Another tool that can help you discover the duplicate content issue on your site is Ahrefs’ site audit tool. Login to the tool and perform a crawl. This will analyze your site thoroughly. Once the crawl gets completed, navigate to the “content quality report.”
The report will highlight the group of duplicates and near duplicates in orange color that are without the canonical tags. You can further click it to witness the affected pages.
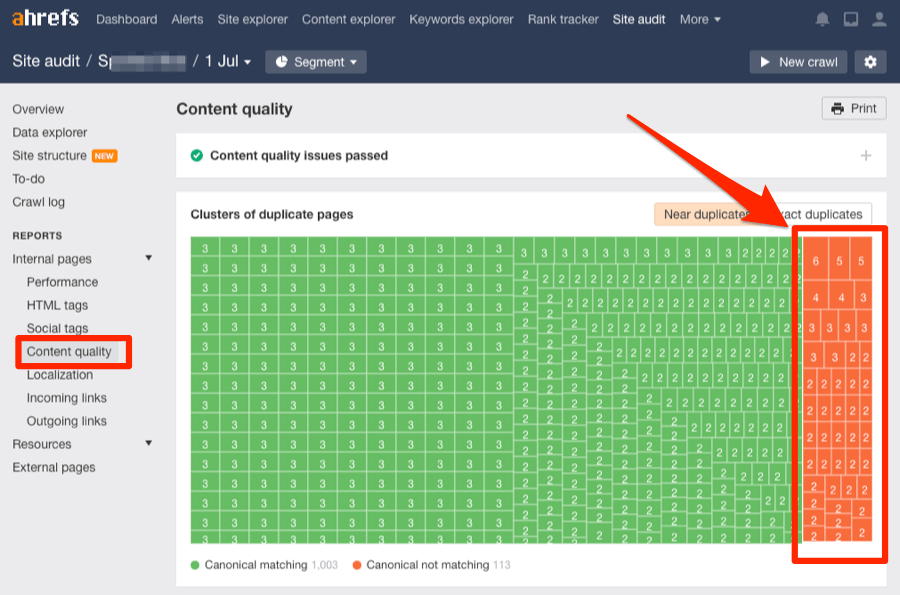
Now, analyze the content and determine the reasons for the content duplication and act accordingly.
Note that these won’t always be issues that need rectifying, especially in the case of near duplicates.
Additionally, its “HTML tags report” can also help you discover duplicate meta descriptions, title tags, and H1.
Under “HTML tags & content”, you will witness a bad duplicate toggle which will display the pages that contain duplicate meta tags but different canonicals.
A yellow graph will appear; you can click on any bar and witness the affected pages of your site and handle them accordingly.
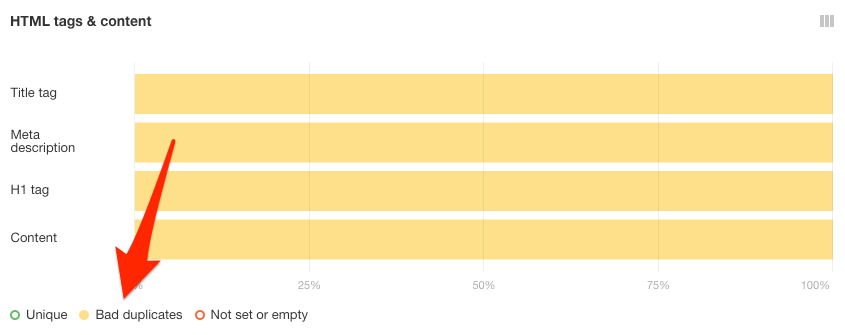
Keep in mind that they are not necessarily issues that need to be fixed. You need to examine carefully and act accordingly.
How to check duplicates over the web?
Besides these, you can also check for duplicates of your content over the internet. As discussed above, this can occur if you syndicate content or your content gets scrapped. To analyze your duplicate content over the web, you can use the Copyscape tool. This will display copies of your content over the web. This is usually not an issue but may become one of the syndicated, or copied content outranks your original one.
# How to Fix Duplicate Content issues?
Although we have already explained how to avoid errors while discussing the errors, let us suggest some measures, in brief, to prevent duplicate content issues and ensure users view the desired content.
1. Using 301 redirects for duplicate contents
You can’t always control your CMS from creating additional URLs for your content; however, you can redirect them. 301 redirects are very effective in managing duplicate content issues. You can easily redirect the duplicates of your content to its main version. While redirecting, always remember to redirect the high-performing page to the lower ones.
2. Using canonical tags for duplicate content
Another method to handle content duplication is to use canonical tags. You can use them when you can’t or don’t want to eliminate your content completely for any reason. You can use canonical tags in the <head> section of the content, which is referred to as canonicalization. By placing this tag, you proactively signal search engines that this URL is your proffered URL among the duplicates that you want to get indexed. Therefore, you can use canonical tags to handle your site’s duplicates.
However, Google Suggests canonicals are slower than redirects. You can prefer using 301 redirects to handle your duplicates mainly. You can use canonicals when using redirects is not possible or when you are unable to or unwilling to remove your identical or near-identical content.
3. Including “links” to the original content
If you are unaware of editing your site’s <head> section, you can’t implement 301 redirects and canonicals. If so, implementing links can be a good approach to handling your duplicates. You can always add internal links in your content, pointing to the original content. Also, if your content is scraped and published with links back to your original content, this might be beneficial to you. Google will notice various links directing to your original content and soon will discover that it’s your canonical version.
4. Be cautious while syndicating your content.
If you practice content syndication, be careful with it. It is best to ask the site you offer your content to link it back to the original content. In addition to it, you can also ask them to noindex the content to prevent search engines from indexing it. If they don’t do so, Google will choose which content to be displayed on the search results on its own, and they might outrank you.
5. Always be consistent with your linking.
Inconsistent linking might confuse Google. Whenever you internally link your content, be sure to link your original and important, and main versions. Prefer only a single version, either www or non-www, HTTPS or HTTP, with a trailing slash (/) or without it.
6. Avoid repetition and add links instead.
In your articles, minimize text repetition and try to avoid it. If you need to add something comparable to what you’ve already covered in another article, give a quick synopsis and link back to the original article so that readers may learn more about it. This will avoid content duplication.
7. Minimize your site’s similar content:
It’s no point in writing similar content and loading your site. If your site contains many similar pages, try to expand each, adding more unique details or merging similar ones to create a single helpful page.
8. Get familiar with your CMS.
Knowing your CMS can be effective in handling content duplication. Many CMSs may show your content in a variety of formats. Knowing how CMS manages your URLs and your content will enable you to act accordingly and prevent this issue.
Note: If you republish other’s content on your site, make sure to canonicalize it to the original one and noindex it. This will let you prevent duplicate content issues.
Final thoughts
Duplicate content is an issue, but you must not stress about it too much. It’s fixable and can reward you with better rankings. Having a few identical or near identical content does not put your site at risk, but it’s bad for SEO and must be fixed timely. Majorly, content duplication occurs due to technical mishappenings and may create tons of duplicates if not handled properly.
When talking about fixes of duplicate content in SEO, it is vital to provide the correct signals to Google for your content to be marked as the original source. This will prevent the issues and keep your site’s SEO healthy.
Here, we’ve gone through the duplicate content issue in depth, including what it is, why it’s bad for SEO, what causes it, how to detect it, and how you can solve it effectively. We hope this has helped you comprehend duplicate content in SEO easily.
Depending on how duplication occurs on your site, you can take appropriate steps and fix them accordingly.
Lastly, we would say focusing on developing unique and fresh content, auditing, and optimizing your site on a regular basis will keep your site fit and help it rank higher and reach the desired audience.